False Positives and Content ID: Why More Musicians Are Finding Their Music Caught in the Algorithm
As YouTube, Facebook, TikTok, and other platforms continue relying on automated copyright detection systems, a growing number of musicians are discovering that the biggest threat to their music may not be piracy — it may be the algorithm itself.
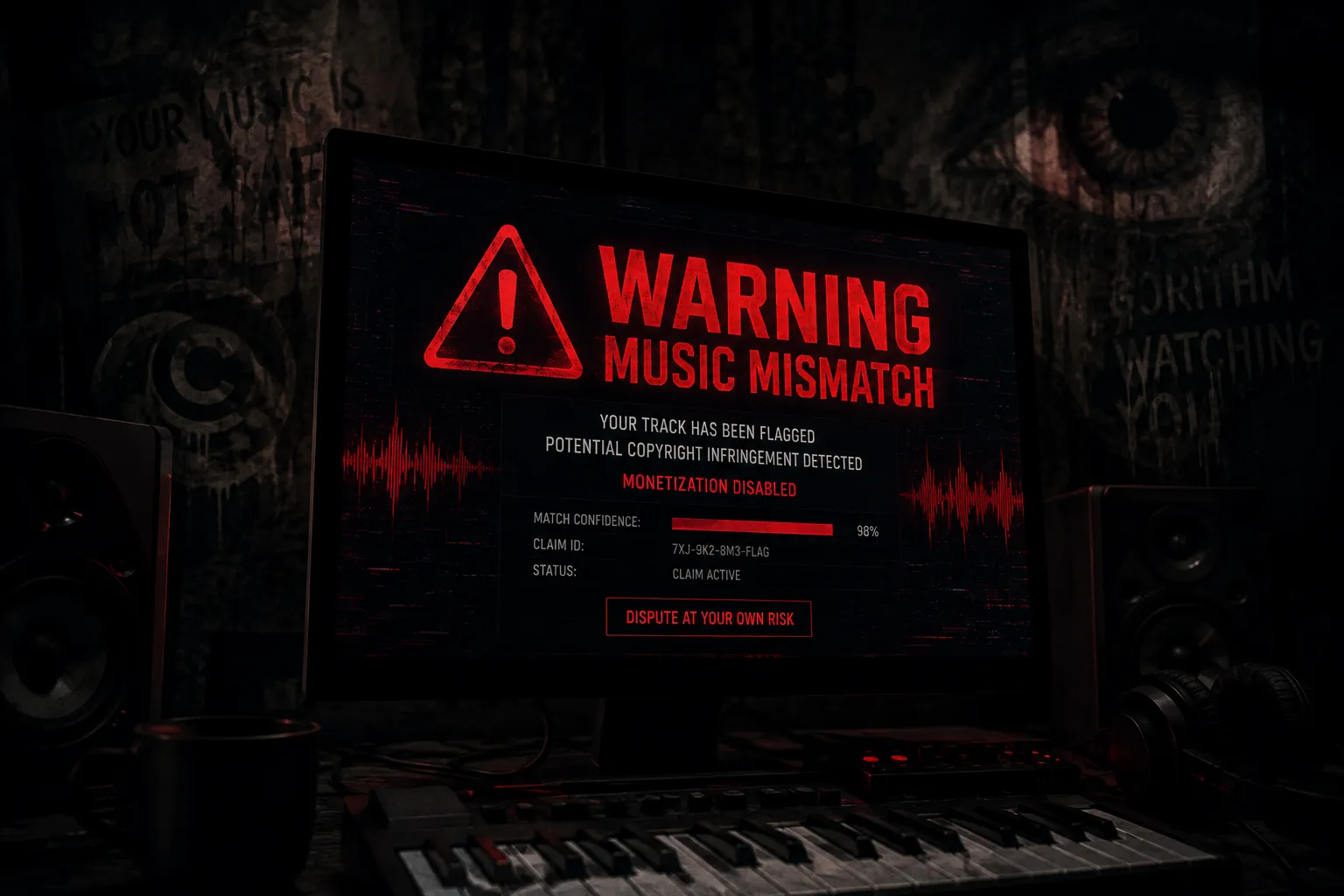
Content ID systems were originally designed to help copyright owners identify unauthorized uses of their work online. In theory, the technology sounds straightforward: compare uploaded audio against a massive database of copyrighted recordings and flag matches. In practice, however, musicians, composers, producers, and copyright scholars have increasingly raised concerns about a growing problem known as false positives.
A 2017 scholarly paper titled "The Dilemma of False Positives: Making Content ID Algorithms More Conducive to Fostering Innovative Fair Use in Music Creation" by Toni Lester and Dessislava Pachamanova examined exactly this issue. Published through the UCLA Entertainment Law Review, the research argues that automated enforcement systems can incorrectly block or claim music that is legally permissible, including transformative works, fair use creations, public domain material, and original compositions that merely contain similar sonic characteristics. The paper is available at: https://doi.org/10.5070/LR8241035525.
The authors note that Content ID systems can generate false positives when algorithms mistakenly identify legal works as infringing content. While copyright owners naturally want protection for their intellectual property, Lester and Pachamanova argue that excessive algorithmic enforcement risks suppressing creativity and discouraging innovation among modern music creators.
The concern has become particularly relevant as more musicians rely on sample libraries, loops, virtual instruments, and royalty-free sound collections. Although these tools are legally licensed and widely used throughout the music industry, some distributors and Content ID providers have begun warning artists that such sounds can create conflicts within automated copyright systems.
One extensive industry discussion on the VI-Control composer forum highlights the confusion many creators face when attempting to use Content ID while also using commercially available sample libraries. In the discussion, available at VI-Control, composers debate whether tracks built with non-exclusive samples should be eligible for Content ID protection at all.
Several distributors, including DistroKid and RouteNote, have published policies stating that tracks containing non-exclusive samples, loops, or publicly available audio may be ineligible for certain Content ID programs. The concern is straightforward: if multiple artists legally use the same commercially available sounds, an automated detection system may incorrectly conclude that one creator owns the other's work.
Forum participants described examples involving exposed drum loops, vocal phrases, construction kits, and other commonly available audio assets. Several composers expressed concern that as detection systems become more sophisticated, the likelihood of accidental matches could actually increase. Others argued that virtual instrument libraries are less likely to trigger problems because they are used to create original performances rather than simply reusing pre-recorded musical phrases.
The scholarly research largely echoes these concerns. Lester and Pachamanova argue that measuring Content ID effectiveness solely by the number of detected matches overlooks the significant costs associated with false positives. A system that aggressively blocks content may successfully stop infringement, but it can also suppress legal expression, transformative works, and entirely original music.
The paper proposes alternative approaches for evaluating algorithmic performance, suggesting that false-positive rates should be considered alongside detection rates when determining whether automated copyright systems are functioning properly. The authors also recommend regulatory reforms that would encourage a more balanced approach between protecting copyright holders and preserving creative freedom.
What makes the issue particularly relevant in 2026 is the sheer volume of music now being created. Millions of songs are uploaded each year to streaming platforms and social media services. At the same time, producers increasingly rely on sample packs, AI-assisted tools, royalty-free libraries, and virtual instruments. As the ecosystem grows more complex, distinguishing infringement from legitimate creation becomes increasingly difficult for automated systems.
For many creators, the debate is no longer theoretical. False claims can delay monetization, block videos, redirect advertising revenue, and create lengthy disputes that take weeks or months to resolve. While copyright enforcement remains essential, critics argue that systems designed to protect creativity should not inadvertently punish the very creators they are supposed to serve.
Nearly a decade after publication, the Lester and Pachamanova study remains highly relevant. As platforms continue expanding automated enforcement and AI-driven content recognition, the challenge identified by the researchers persists: how can technology effectively protect copyright without stifling innovation?
Until that balance is achieved, musicians may continue finding themselves in a strange position — legally creating music, yet still having to convince an algorithm that they own it.








